Извлечение ключевых терминов
Общая архитектура разработанной системы представлена на рис. 1.

Рис. 1. Общая архитектура системы.
Для получения информации о сообщениях пользователя с сервера Twitter использовался Perl-модуль Net::Twitter. Результатом взаимодействия с Twitter API является получение некоторого числа последних сообщений его аккаунта, иначе называемых timeline.
Для решения поставленной задачи был выбран метод statuses/friends_timeline, возвращающий сообщения друзей пользователя. Для тестирования были созданы аккаунты, подписанные на обновления статуса единственного друга. При этом в самом аккаунте не публиковалось никаких сообщений. Таким образом, результат вызова данного метода содержит лишь необходимое количество сообщений одного пользователя Twitter, что и требуется в качестве исходных данных.
В процессе предварительной обработки текста, или препроцессинга, содержимое полученных с сервера Twitter сообщений преобразуется к формату входных данных для алгоритма извлечения ключевых терминов.
Помимо стандартных для этого этапа операций, производится также удаление слэштегов и @-ссылок, а также служебных слов «RT» и «RETWEET», то есть тех элементов специфического синтаксиса Twitter, которые не несут смысловой нагрузки и являются стоп-словами в терминах обработки естественного языка. На этом этапе также производится извлечение хэштегов, которые в последующем обрабатываются наравне с остальными словами.
Очевидно, однако, что для составления списка кандидатов в ключевые термины недостаточно лишь исходной последовательности слов. Исходя из небольшой длины сообщений, представляется возможным сделать алгоритм максимально избыточным с целью повышения полноты результатов, то есть не пропустить ни один возможный ключевой термин, из скольких бы слов он ни состоял. С этой целью производится поиск всех возможных N-грамм, то есть последовательностей идущих друг за другом слов. Количество N-грамм Qk, которые можно получить из k слов (включая N-граммы из одного слова), таким образом, равно:
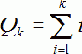 | (3) |
Все полученные на этом этапе термины добавляются в массив возможных ключевых терминов.
Завершающим этапом препроцессинга является стоплистинг, т.е. удаление из полученного массива тех слов, которые не несут существенной смысловой нагрузки. Важно отметить, что стоплистинг выполняется лишь после извлечения N-грамм. Таким образом, стоп-слова могут входить в составные термины, но удаляются из списка кандидатов, если встречаются в нём сами по себе. На этом этапе используется стоп-лист системы SMART .
На этапе расчёта весов терминов-кандидатов для каждого из них запрашивается значение информативности из базы данных. Вторым необходимым для расчётов показателем является частота встречаемости термина TF. Для каждого найденного в БД термина его вес рассчитывается по формуле (2).
Общий принцип извлечения ключевых терминов заключается в анализе заданного числа сообщений и определении порогового значения веса для каждого из них. Те термины, веса которых больше или равны пороговому значению, считаются ключевыми.
Изначально пороговым считается среднее арифметическое для всех терминов-кандидатов значение веса. Все последующие операции призваны уточнить его и улучшить результаты работы алгоритма в целом.
Следующим этапом является обработка массива хэштегов, полученного на этапе препроцессинга. Предполагается, что с их помощью пользователь явно указывает термины, определяющие тематику сообщения. Поэтому логично предположить, что пороговое значение для всего сообщения не должно быть выше минимального веса среди его хэштегов. Основываясь на этом предположении, вес каждого из хэштегов (если он был найден в БД) сравнивается с текущим пороговым значением и понижает его в случае, если оно больше.
Если после обработки хэштегов пороговое значение осталось равным 0 (в случае, когда они не были указаны или когда ни один из них не был найден в БД) либо превышает найденное среднее значение, оно принимается равным среднему. Такая ситуация на практике встречается чаще всего, так как пользователи редко явно указывают тематические термины.
Однако в противном случае такой подход существенно улучшает результаты работы.
Нужно отметить, что сообщения обрабатываются в порядке, обратном поступлению с сервера, то есть в прямом хронологическом. Такой подход представляется логичным и учитывает специфику сервиса блогов в целом: пользователь может написать сообщение на какую-то тему, а затем вернуться к ней снова. Однако во втором сообщении, помимо тех терминов, которые были выбраны ключевыми в первом, могут быть другие, более информативные термины, за счёт которых пороговое значение для второго сообщения будет завышено, и ключевые термины из первого сообщения не будут выделены. Чтобы избежать этого, в системе имеется отдельный массив, содержащий все ранее извлечённые ключевые термины. Тогда при обработке очередного сообщения термины из этого массива будут безусловно извлечены и снизят пороговое значение веса для данного сообщения.
В этом контексте важно, что при непосредственном выборе ключевых терминов кандидаты обрабатываются в порядке возрастания их весов. Таким образом, если вес какого-либо из кандидатов ниже порогового, но он выбирается ключевым из-за того, что присутствует в массиве ранее извлечённых терминов, то пороговое значение становится равным его весу, и все следующие термины автоматически попадают в список ключевых.
Результатом работы алгоритма является список отсортированных в порядке убывания весов ключевых терминов.
