Существующие подходы к извлечению ключевых терминов
Одной из задач извлечения информации из текста является выделение ключевых терминов, с определённой степенью достоверности отражающих тематическую направленность документа. Автоматическое извлечение ключевых терминов можно определить как автоматическое выделение важных тематических терминов в документе. Оно является одной из подзадач более общей задачи – автоматической генерации ключевых терминов, для которой выделенные ключевые термины не обязательно должны присутствовать в данном документе . В последние годы было создано множество подходов, позволяющих проводить анализ наборов документов различного размера и извлекать ключевые термины, состоящие из одного, двух и более слов.
Важнейшим этапом извлечения ключевых терминов является расчёт их весов в анализируемом документе, что позволяет оценить их значимость относительно друг друга в данном контексте. Для решения этой задачи существует множество подходов, которые условно делятся на 2 группы: требующие обучения и не требующие обучения. Под обучением подразумевается необходимость предварительной обработки исходного корпуса текстов с целью извлечения информации о частоте встречаемости терминов во всём корпусе. Другими словами, для определения значимости термина в данном документе необходимо сначала проанализировать всю коллекцию документов, к которой он принадлежит. Альтернативным подходом является использование лингвистических онтологий, которые являются более или менее приближёнными моделями существующего набора слов заданного языка. На базе обоих подходов были созданы системы для автоматической экстракции ключевых терминов, однако в этом направлении постоянно ведутся работы с целью повышения точности и полноты результатов, а также с целью использования методов извлечения информации из текста для решения новых задач .
Самыми распространёнными схемами для расчёта весов терминов являются TF-IDF и различные его варианты, а также некоторые другие (ATC, Okapi, LTU). Однако общей особенностью этих схем является то, что они требуют наличия информации, полученной из всей коллекции документов.
Другими словами, если метод, основанный на TF-IDF, используется для создания представления о документе, то поступление нового документа в коллекцию потребует пересчёта весов терминов во всех документах. Следовательно, любые приложения, основанные на значениях весов терминов в документе, также будут затронуты. Это в значительной мере препятствует использованию методов извлечения ключевых терминов, требующих обучения, в системах, где динамические потоки данных должны обрабатываться в реальном времени, например, для обработки сообщений микроблогов .
Для решения этой проблемы было предложено несколько подходов, таких как алгоритм TF-ICF . В качестве развития этой идеи Mihalcea и Csomai в 2007 году предложили использовать в качестве обучающего тезауруса Википедию . Они применили для расчётов информацию, содержащуюся в аннотированных статьях энциклопедии с вручную выделенными ключевыми терминами. Для оценки вероятности того, что термин будет выбран ключевым в новом документе, используется формула:
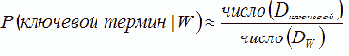 | (1) |
- W — термин;
- Dключевой — документ, в котором термин был выбран ключевым;
- DW — документ, в котором термин появился хотя бы один раз.
Эта оценка была названа авторами keyphraseness (в данной работе определена как информативность). Она может быть интерпретирована следующим образом: «чем чаще термин был выбран ключевым из числа его общего количества появлений, тем с большей вероятностью он будет выбран таковым снова».
Информативность может принимать значения от 0 до 1. Чем она выше, тем выше значимость термина в анализируемом контексте. Например, для термина «Of course» в Википедии существует только одна статья, посвящённая песне американского исполнителя, поэтому он редко выбирается ключевым, хотя встречается в тексте очень часто. Значение его информативности, таким образом, будет близко к 0. Напротив, термин «Microsoft» в тексте любой статьи почти всегда будет выделен ключевым, что приближает его информативность к 1.
Данный подход является довольно точным, т.к.
все статьи в Википедии вручную аннотируются ключевыми терминами, поэтому предложенная оценка их реальной информативности является лишь результатом обработки мнений людей.
Вместе с тем, эта оценка может быть ненадёжной в тех случаях, когда используемые для расчётов значения слишком малы. Для решения этой проблемы авторы рекомендуют рассматривать только те термины, которые появляются в Википедии не менее 5 раз.
В заключение обзора методов извлечения ключевых терминов нужно сказать, что для расчёта веса термина в данной работе использовалась формула:
| (2) |
- i — порядковый номер термина;
- TFi — частота термина в анализируемом сообщении;
- Ki — информативность термина по данным Википедии.
TF означает частоту термина (Term Frequency). Значение этого компонента формулы равно отношению числа вхождения некоторого термина к общему количеству терминов сообщения. Таким образом, оценивается важность термина ti в пределах отдельного сообщения.
