Поиск корзин просмотров страниц
Поскольку SQL/MR-функция может поддерживать свои собственные структуры данных, она может производить однопроходный анализ данных, для выполнения над которыми запросов на чистом SQL требуется несколько проходов. Для демонстрации этой особенности мы рассмотрим задачу нахождения корзин просмотров страниц (basket of page views), содержащих заданный набор страниц. Для выполнения этого эксперимента мы использовали те же, что и ранее, данные о посещении страниц Web-сайта. Для выполнения запросов использовалась СУБД nCluster, работающая на кластере с 13 узлами. Теперь набор кликов каждого пользователя считается его корзиной просмотров страниц. Кроме того, мы определяем один или несколько наборов страниц, каждый из которых называется "поисковым набором". Корзина данного пользователя удовлетворяет условию этого запроса, если хотя бы один поисковый набор полностью содержится в корзине просмотров страниц этого пользователя. В каждом поисковом наборе может содержаться любое число различных страниц. Для решения этой задачи были созданы SQL- и SQL/MR-запросы. На рис. 13 показана нормализованная производительность выполнения этих запросов при возрастании размеров поискового набора.
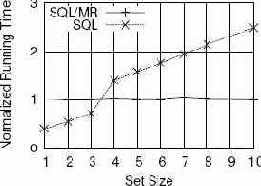
Рис. 13. Время нахождения корзин просмотров страниц, соответствующих заданным наборам страниц, с использованием SQL и SQL/MR.
Производительность обработки SQL-запроса деградирует по мере увеличения размеров наибольшего поскового набора. Так происходит из-за того, что для сборки корзин кликов, которые сравниваются с поисковыми наборами, используются соединения таблицы кликов с ней же самой. Для сборки в пользовательскую корзину всех наборов размера n требуется n-1 самосоединений таблицы кликов. Наиболее оптимизированный SQL-запрос, который нам удалось написать, слишком велик, чтобы можно было здесь его показать. Когда поисковый набор является небольшим, SQL-запрос выполняется производительнее SQL/MR-запроса, поскольку запрос с нулевым или небольшим числом соединений сравнительно просто оптимизируется и обрабатывается.
При возрастании числа самосоединений усложняется и оптимизация, и обработка запроса. На самом деле, мы обнаружили, что задание нескольких поисковых наборов, особенно, разного размера существенно влияет на эффективность выполнения SQL-запроса. Время выполнения, показанное на рис. 14, относится к SQL-запросам, обрабатывемых наилучшим образом, – к тем запросам, для которых задается только один поисковый набор.
Ниже показан запрос с вызовом SQL/MR-функции findset, решающий ту же задачу. В разделе SETID указывается атрибут разделения корзин, а в разделе SETITEM – атрибут, являющийся предметом корзины. Каждый раздел SETn определяет один поисковый набор.
SELECT userid FROM findset( ON clicks PARTITION BY userid SETID(’userid’) SETITEM(’pageid’) SET1(’0’,’1’,’2’) SET2(’3’,’10) )
В отличие от производительности SQL, на производительность SQL/MR не влияют ни размер поискового набора, ни число этих наборов, поскольку требуется всего один проход по данным. В течение этого прохода производится всего лишь учет того факта, включают ли клики данного пользователя какой-либо возможный набор страниц. SQL/MR-запрос также проще расширить дополнительными поисковыми наборами, просто добавив новые разделы аргументов SETn. Добавление более крупного поискового набора к SQL-запросу потребовало бы дополнительных самосоединений. Прим. переводчика. Комментарий по поводу этого раздела оказался настолько объемным, что пришлось выделить его в отдельную заметку «SQL и MapReduce: новые возможности или латание старых дыр?».
1 Функция tokenizer реализована так, что создает токены для всех столбцов символьного типа входной таблицы, используя указанный разделитель. Для каждого несимвольного столбца возвращается один токен. Можно было бы легко расширить tokenizer, добавив еще один раздел аргументов, в котором указывалось бы, какие столбцы входной таблицы следует обрабатывать.
2 По умолчанию SQL/MR-функции разрабатываются как параллельные. Однако существуют ситуации, в которых требуется последовательная обработка данных.Для удовлетворения этой потребности мы допускаем наличие константы в разделе PARTITION BY. Это приводит к тому, что все входные данные собираются в одном рабочем узле и затем обрабатывются последовательно указанной SQL/MR-функцией. Пользователь предупреждается, что эта SQL/MR-функция не будет выполняться параллельно.
