Классика баз данных - статьи
«Входная» и «выходная» обработка
В модель СУБД, по существу, встраивается то, что мы называем «выходной» («outbound») обработкой, схема которой показана на рис. 4. На первом шаге данные заносятся в базу данных. После индексирования данных и фиксации транзакции эти данные становятся доступными для последующего выполнения запросов (шаг 2), после чего данные представляются пользователю (шаг 3). Эта модель «обработки после сохранения» лежит в основе всех традиционных СУБД, что и не удивительно, поскольку, в конце концов, основной функцией СУБД является принятие данных с тем, чтобы они никогда не были утрачены.
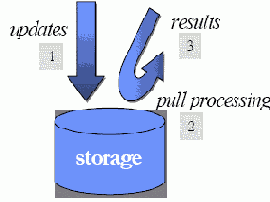
Рис. 4. «Выходная» обработка
В приложениях реального времени операция сохранения данных, которая должна выполняться до их обработки, увеличивает как время задержки в приложении, так и стоимость обработки сообщения приложением. Альтернативная модель обработки, в которой удается избежать узкого места сохранения данных, показана на рис. 5. В этой модели входные потоки проталкиваются в систему (шаг 1) и обрабатываются «на лету» в основной памятью сетью запросов (шаг 2). Затем результаты выталкиваются в клиентские приложения для их конечного потребления (шаг 3). Чтение из области постоянного хранения и запись в нее являются необязательными, и во многих случаях, когда в них возникает необходимость, выполняются асинхронно. Тот факт, что область постоянного хранения отсутствует или является необязательной, позволяет сократить и стоимость обработки, и время задержки, что приводит к существенно более высокой производительности. Именно эта модель «входной» обработки используется в системе обработки потоковых данных StreamBase.
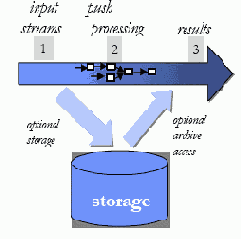
Рис. 5. «Входная» обработка
Конечно, может возникнуть вопрос «А не может ли и СУБД производить входную обработку?». СУБД исходно разрабатывались, как серверы выходной обработки данных, но много лет спустя в них были внедрены механизмы триггеров.
